The Case for Decentralizing Links
One might say the web cannot be trusted, in so far as it continues to be driven by a centralized, greed-influenced, wealth-reinforcing linking model.
The link (aka the hyperlink) is the fundamental building block that literally shapes the web. The link governs how information is connected, in the current case, on pages. One might think the hyperlink is decentralized because page authors are decentralized. But in fact, any given page and its links are centralized, with only the page author being able to connect supra-information to the page.

This article explores how decentralizing the fundamental building block of the web–the link — could change everything. Decentralizing the link would enable anyone to create and connect related content to an idea, thereby creating a fully democratic Internet of Ideas. The world would enjoy many benefits including censorship-free and virtually instantaneous content discovery including long tail, accelerated learning, and built-in truth verification.
The Internet Of Pages
Today’s Internet is an Internet of pages connected by links. The links are best suited for direct linking to an entire page. Examples include from a website mention to the actual website, from a product mention to places where it can be purchased, from a video mention to the video page, and from a call-to-action to a form. This Pages-Connected-By-Links structure optimizes for linear reading of an article from top to the bottom.
The resulting “Internet of Pages,” however, is not well suited for non-linear activities such as reading snippets of various pages while researching a topic, mostly because of the relative paucity of external links and the capitalistic nature of the links of themselves. For this activity, the user generally relies on search as a navigation tool.
Theoretically, the existing linking structure could adequately support non-linear reading and to a certain extent discovery, but external links are generally scarce on the web. With notable exceptions such as Wikipedia, the vast majority of sites have mostly internal links, linking to other pages on the same site that may or may not be strongly related to the information on any specific page.
The potential for external links is often limited by the knowledge of page authors who may be unaware of related resources and/or have not taken the time to adequately research the topic they are writing about.
When external links do exist, one has little idea where they lead. The actual information that is linked-from can provide a clue though it may not necessarily be related to what it is linked-to. Another clue, though often cryptic and unreliable, can be had by hovering the cursor over a hyperlink to display the destination URL along the bottom row of the browser.

Unfortunately, one can have little trust that the link was not made for capitalistic reasons, such as a paid advertorial, or to gain a higher search engine ranking. Almost all search engines use these incoming links to see what pages are “supposedly” best. This has long been gamed, making the link graph — an organized and scored list of incoming links to a site for search engine ranking — next to useless when determining genuine “supra-informational” relations.
Furthermore, and quite simply, only the richer end of society can afford the resources in money, time, and never-ending indignant opinion, to craft the current blogosphere, thus providing an additional wealth-threshold censorship model to not only said content, but said link graph centralized therein.
One might say the web cannot be trusted, in so far as it continues to be driven by a centralized, greed-influenced, wealth-reinforcing linking model.
Hyperlinks Used to Be Called Jump Links
A hyperlink is akin to jumping off a cliff — one doesn’t know where they will land or if anything will be there to land on. In fact, before links were adopted as the fundamental building block of the web, they were called “jump links” and considered by some to be quite radical. While they did provide a very simple, elegant structure for the web at first blush, twenty years down the road, they seem to have locked us into seemingly intractable problems such as fake news, an overabundance of digital flotsam and low quality content, a lack of transparency, and powerful digital monopolies.

Common usage of jump links,aesthetics, and technical limitations limit the scope of what may be linked-from to short phrases and images. Linking from sentences or paragraphs, while technically possible, looks quite unappealing as a permanent fixture on the page and can be distracting. Too many links in a paragraph — even from short phrases or words — can also be distracting.
On the other end, jump links can only link to the top of a page or a point within a page. They cannot directly link to specific piece of content within the web page context. (They can link directly to an image but not to an image within a web page.) Some video platforms such as YouTube allow links directly to a specific point in a video but these are custom implementations and they do not have the notion of an endpoint.
Furthermore, since the beginning of the web, the limitation of one link for a given piece of text or image has locked many into the view that (non-promotional) links are simply for connecting text to its source information. Links are generally seen as more or less a digital citation or footnote. While links to source material can be extremely useful, the focus on this single use case and the infeasibility of multiple links from a single idea tends to inhibit one from thinking about (non-promotional) linking to things other than said source material as well as imagining the extent to which multiple links could in fact be desirable.
Jump links are also constrained by the page author’s capacity for adding supra-information to their pages. Often, the page author does not have the knowledge, time, energy, or inclination to link to valuable supplementary information that could enhance understanding and learning.
A “feature” of jump links that ultimately led to its adoption is that they are uni-directional, and therefore simple and elegant. The page being linked to does not need to know that it is being linked to. As an example, within the context of a link from Page A to Page B, Page A knows it links to Page B yet Page B is oblivious to Page A’s existence. This enables a web author to simply link to a page without worrying about anything other the location of the page. They do not have to ask permission. They do not have to worry if the page changes as long as its location stays the same.
Unsurprisingly, the uni-directional feature of the linking created a market need and an opportunity to provide the service of tracking what pages link to a given page and which users click through the link. This information underlies the online search, advertising, and analytics industries. Just imagine if links themselves and other UI objects tracked such activity — we’d likely have a different web on many levels.
In a sense, one could say that today’s link is not only the foundation of the Internet of Pages, but also of Google’s dominance. Before Google, search engines were simply looking for relevancy in the dataset with respect to search terms. Google innovated with an algorithm that prioritized sites within the relevant set based on the number of incoming links to the page. Google used a bot called a “spider” to gather metadata, traverse links, and count the number of times each page was linked to. The results were much better and faster than the then-dominant Altavista search engine, which was quickly rendered to oblivion by the incoming link-aware Google juggernaut.
The Hyperlink was Not the Only Proposal
Before the hyperlink that undergirds the Internet of Pageswas developed by Tim Berners-Lee to share documents among his colleagues at CERN, there were proposals for different types of links that could have created a more trustable, evidence-based Internet. In the early 1960’s, Ted Nelson was the first to mock up a personal computer and coined the term”hypertext” which represents the “ht” in “http” (hypertext transport protocol). Nelson and his Project Xanadu advocated for bi-directional links that know when something is linking to it, as well as parallel pages connected by visible links from an idea to its source.
Nelson explains “The xanalogical content link is not embedded. It is ‘applicative’ — applying from outside to content which is already in place with stable addresses. Xanalogical links are effectively overlays superimposed on contents. Any number of links, comments, etc., created by anyone anywhere, may be applied to a given body of content. By this method it is possible to have thousands of overlapping links on the same body of content, created without coordination by many users around the world.”
In Who Owns the Future, Jaron Lanier explains the implications of Nelson’s vision:
A core technical difference between a Nelsonian network and what we have become familiar with online is that [Nelson’s] network links were two-way instead of one-way. In a network with two-way links, each node knows what other nodes are linked to it… Two-way linking would preserve context. It’s a small simple change in how online information should be stored that couldn’t have vaster implications for culture and the economy.
The Decentralized Web Summit 2018 — convened by the Internet Archive on July 31-Aug 2, 2018 — featured talks with Ted Nelson and Tim Berners-Lee. Nelson expressed disappointment and frustration that parallel pages with visible links have not been adopted for the web. And vowed to continue on with the struggle.
Berners-Lee was upbeat about the possibility that his MIT-based project Solid — a set of conventions and tools that separate app logic and data storage — will enable a wave of decentralized social applications to compete with the centralized social media giants. Solid enables people to be autonomous participants on the Web, controlling their data, sharing it with whomever they want to, as well as allowing different applications to be used on the same data. It is literally the opposite of the vendor lock-in that users experience with Facebook et al.
dokieli — an application that speaks to the Solid server — has been working on decentralized linking since late 2015. dokieli is a browser extension and Javascript script library for decentralized article publishing, annotations, and social interactions. dokieli enables users to attach annotations including citation links to any piece of text anywhere on the web. The creator of dokieli, Sarven Capadisli, likes to say “”dokieli enables the Write dimension of the Read-Write Web.” He notes that dokieli is the first application to enable sharing and reuse of annotations across applications, regardless of how they were generated.
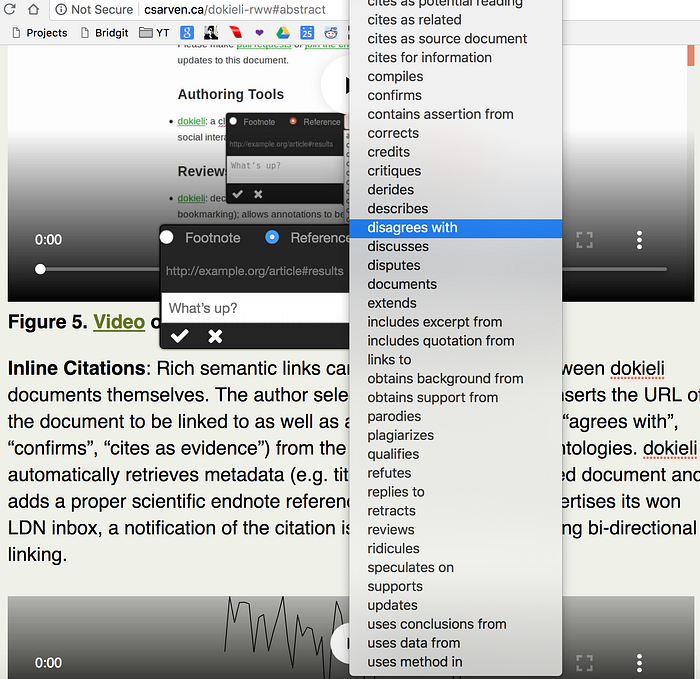
Which respect to linking, dokieli enables anyone to create rich semantic links between text and a web page. A user selects a text fragment and inserts the URL of the document to be linked to as well as a semantic link type (e.g., agrees with, disagrees, cites as evidence). dokieli extracts metadata (e.g., title, authors) from the linked document and adds a proper scientific endnote reference to the page with the text fragment. If the linked document is connected to a Linked Data Network, a notification of the citation is posted, thus providing for bi-directional linking of citations.
This progress notwithstanding, ubiquitous, one-to-many, decentralized, bi-directional links that go beyond source material are key to building a transparent and trustable next generation web. Had Nelson’s ideas about bi-directional links been adopted, we would have a quite different world wide web then we do today. It might not be as vast, but it would have a higher signal-to-noise ratio, greater transparency, less piracy, and less fake news.
Building the Internet of Ideas, One Bridge at a Time
My organization — Bridgit, S.P.C. — is building a new connective layer overlaying the Internet of Pages. Bridgit enables the crowd to build a supra-information layer on top of the Internet that connects information on an idea-by-idea basis. We call this the Internet of Ideas.
Think about the night sky during a new moon over the countryside far away from city lights. A universe of stars shine brightly across the unfamiliarly dark sky. Visible throughout the world, Orion is a prominent constellation located on the celestial equator. Named after a hunter in Greek mythology, Orion is one of the most conspicuous and recognizable constellations. Yet to the untrained eyes unaware of the patterns formed by the stars, Orion is invisible in plain sight. It is the same with ideas.

Now imagine that each star is an idea on a page on the Internet. The ideas seem disconnected. By themselves, ideas may have little import like solitary stars to a constellation seeker. For example, we do not know whether the idea has any basis in fact or have any supporting information that help support a claim or a perspective. We do not understand the context or the implications. We don’t know what the research says or the anecdotal stories of real life people. But we know that they ideas are connected through the abstraction of pages. We do not see the connections because they are indirect and therefore invisible from our vantage point. Hence, the import of search.
I am seeking for the bridge which leans from the visible to the invisible through reality ~ Max Beckmann
One might ask, why doesn’t search work for the Internet of Pages. Search uses one set of metadata for an entire page. But a large page could easily have hundreds of ideas in it when you consider the text, images, and/or videos. For search to be effective on an idea basis, each idea on a page would need to have its own metadata. Of course, additionally, said page would need to be indexed, which again is not a foregone conclusion considering Google only indexes a fraction of the pages on the Internet.
To obviate the need for search in many use cases, Bridgit is building bridges that connect ideas into constellations of context. Once ideas are connected into a constellation, meaning can be discerned just as the lines between the stars in the constellation bring Orion to life.
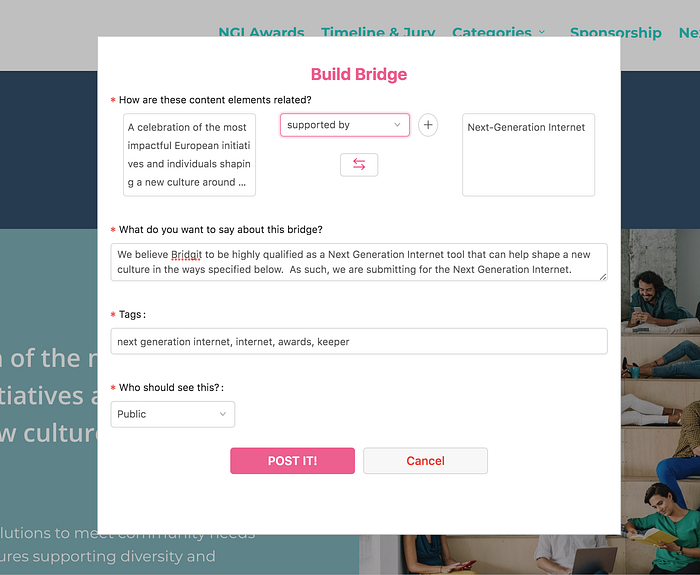
In Bridgit’s world, a bridge is a bi-directional conceptual link between an idea in one place and an idea in another place that defines the semantic relationship between the ideas (e.g., supporting, contradicting). The bridge can encode and track additional information as needed. Multiple bridges can be attached to a single idea.
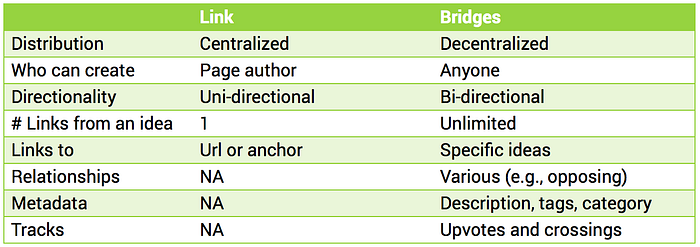
The table below shows the basic differences between bridges and hyperlinks in the most general of applications. More complex applications use advanced and optional situation-specific features.
Bridgit is a browser overlay extension (and in the future an extensible browser) that enables users — whom we call “Bridgers” — to organize, share, and monetize the research they are already doing.
Bridgers are people who already compulsively research their topics of interest on the web, seeking new information and perspectives that help them understand “the why.” They talk about “connecting the dots.” They see the concept of a “bridge” as a powerful metaphor for what is needed.
For Bridgers, virtually all research is deep search on the Internet, the deep web potentially including information behind paywalls, and in some cases the dark web. Bridgers combine a drive to learn more about a topic with an understanding of keywords, search terms, advanced search expressions, and which search engines are best for specific use cases. They can spend hours a day searching on the internet.
Bridgers discover and learn the most amazing things. They find needles in digital haystacks.They have frequent breakthroughs in understanding.
But until now, they haven’t had effective options to organize, share, or monetize what they learn.
Usually the best that they can do is write a blog post or make a YouTube video about what they have learned. But that’s a lot of work, especially if they have a day job. Furthermore, the potential exposure is fleeting as well as limited if they do not already have an established audience. So they usually end up relegating their amazing discovery to a Google doc or Evernote, texting or emailing it to themselves or to friends, bookmarking it, or posting it on a Telegram group or their Facebook Wall. Here today, gone tomorrow.
The Power of Bridges
Bridgit enables internet researchers to organize, share, attract eyeballs, and monetize the deep search they are already doing. They do this by building “bridges,” which are essentially annotated links between ideas on different pages. Each idea can be a paragraph, a phrase, a part of an image, a segment of a video. The bridge has a type that reflects the relationship between the ideas (e.g., supporting, opposing).
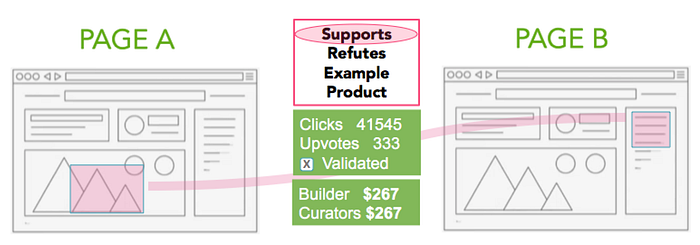
Unlike hyperlinks which support at most one link per piece of text or image, any given idea (including images parts and video and audio segments) can have as many bridges as needed to fully express the extent to which other ideas on the web are related to it.
The only true voyage of discovery, the only fountain of Eternal Youth, would be not to visit strange lands but to possess other eyes, to behold the universe through the eyes of another, of a hundred others, to behold the hundred universes that each of them beholds, that each of them is…
~ Marcel Proust
The multiple bridges associated with a single idea can present diverse sources, supporting ideas and evidence, similar ideas, differing perspectives, and more. The only constraints on bridge content are the imagination of the Bridger community rather than the page author. In these senses, bridges are a quantum improvement over the hyperlink, providing a large pallette for Bridgers to create connections between ideas.
Bridgers are rewarded in the Bridgit currency based on the value their bridges add to the network based on up-votes and bridge crossings (i.e., the equivalent of a clickthrough for a link).
Bridgit essentially “tokenizes” their research.
Bridgit is building a ecosystem which includes Bridgers, search users, web sites, advertisers, web marketing companies, and organizations that want to engage with their audience around information and content.
The initial focus categories will be sports, food, politics, health, celebrities, hip hop, and blockchain/crypto. We are excited to see what kinds of bridges and what categories create the most value in the network. Will it be the U.S. midterm elections, football or futbol, the star of the hot new movie, cats, or all of the above? What aspects of which pages will be shown to be false, misleading, fake, or unsubstantiated?
Bridgit is building an inclusive community that provides income opportunities for people of all backgrounds and major languages. In our view, peoples of all persuasions have aspects of awareness as well as blind spots. By holding space for different perspectives and bridging different languages, Bridgit creates the possibility that different peoples can learn from one another.
We believe marginalized peoples who have developed skills and world views to ameliorate if not thrive in challenging circumstances have much know-how to share with more affluent communities through a platform like Bridgit. We also see enterprising individuals and groups in lower income communities and developing countries creating businesses around building bridges and/or offering bridgework services to the developed world.
As the Bridgit community gains steam, we further imagine the possibility of a digital gold rush similar in some ways to domain registration, which rewards creativity, insight, and breakthroughs while creating the possibility of robust revenue streams that transcend technology cycles and a rich data source for supra-information interactions, next generation apps, chat bots, and search engines.
To the extent Bridgers build out the Internet of Ideas for any given topic, we have the possibility of orders of magnitudes faster content discovery, active discernment of what is fake and real, and enhanced opportunities for learning breakthroughs and creativity. Thus, by decentralizing links, we resolve some of the more intractable problems of the web, thereby creating the possibility of a knowledge foundation for collective understanding and wisdom that can help fulfill the original promise of the Internet.

More where this came from
This story is published in Noteworthy, where thousands come every day to learn about the people & ideas shaping the products we love.
Follow our publication to see more product & design stories featured by the Journal team.
